Formal Concept Analysis with Rust (3) - Parallization
上一篇文章实现了一个简单的Formal Concept的Enumerator。不过实际测试结果表明单纯列举的速度并不足以对应足够大的数据。至少对3000个Object就花掉接近8分钟的算法很难让人接受。这次将利用tokio将上一篇里的算法并行化,来看一看改进之后的速度。
Iterator-style Enumeration
在动手加入多线程之前,先来把上一次写的代码整理一下。上一篇里用了普通的for obj in cur_obj..r.row.len() { ... }的循环,虽然没有什么问题,但可以写的更加"rust风"一点,比如用上Iterator:
(cur_obj..r.row.len())
.filter(|obj| !cur_concept.extent.get(*obj).unwrap_or(false))
.filter_map(|obj| {
let mut extent = cur_concept.extent.clone();
extent.set(obj, true);
let concept = closure(&r, &extent);
let mask = BitVec::from_fn(r.row.len(), |i| if i < obj { true } else { false });
let mut cur_left = cur_concept.extent.clone();
cur_left.and(&mask);
let mut new_left = concept.extent.clone();
new_left.and(&mask);
if cur_left == new_left {
Some((obj, concept))
} else {
None
}
})
.for_each(|(obj, concept)| enumerate_fc(concept, obj + 1, r.clone(), should_print));
这里把之前的for .. in改成了一个Range的Iterator,首先通过一个filter去掉那些已经被加进来的concept,然后通过filter_map进行计算,最后用一个for_each对所有的结果进行递归。这里为了简单没有对filter_map进行更细的切分,如果你愿意实际上可以把它们写成更小的模块:
(cur_obj..r.row.len())
.filter(|obj| !cur_concept.extent.get(*obj).unwrap_or(false)) // filter out existed branches
.map(|obj| {
let mut extent = cur_concept.extent.clone();
extent.set(obj, true);
(obj, closure(&r, &extent))
}) // calculate closure
.filter(|(obj, concept)| {
let mask = BitVec::from_fn(r.row.len(), |i| if i < obj { true } else { false });
let mut cur_left = cur_concept.extent.clone();
cur_left.and(&mask);
let mut new_left = concept.extent.clone();
new_left.and(&mask);
cur_left == new_left
}) // filter out processed branches
....
你或许会担心Iterator对性能的影响,但根据官方的说法,Iterator对性能的影响是微乎其微的,而实际的测试也证明了这一点:
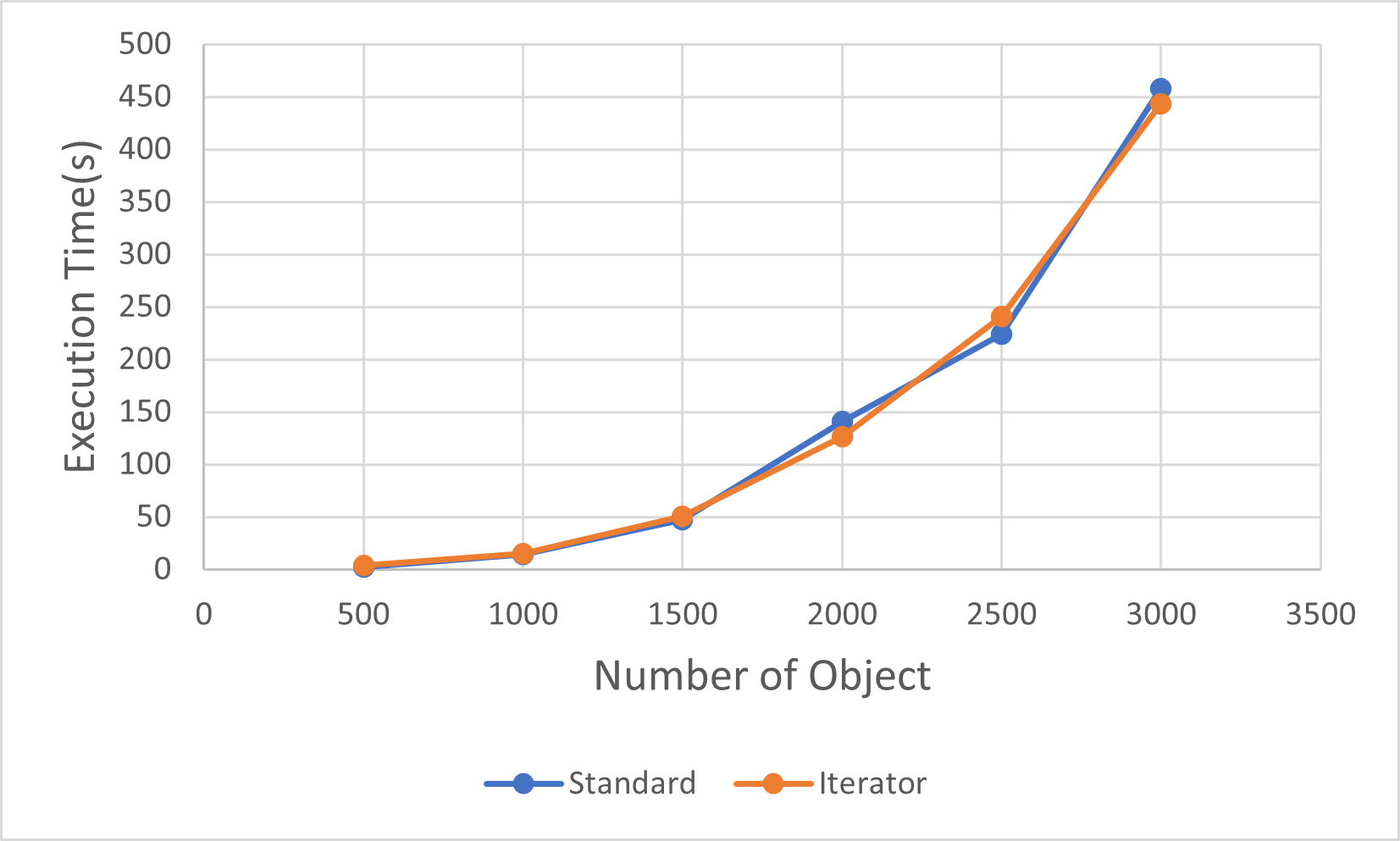
蓝色的线是普通的for-loop,而橙色的线是上面的Iterator,可以虽然没有像Rust的文档里面声称的Iterator快于普通的循环,但二者总体上并没有性能差。相比于性能,Iterator能够带来更好的代码模块化(可读性),这一点更加重要。
Straightforward Parallization
下面把这个算法写成多线程的版本,不用参考论文也能看到,其实只要把for_each里面的递归改成新的线程就能够实现一个简单的多线程版本了,因此先来动手去实现它。
首先需要一个多线程的环境,就像最初所说的,这里用了tokio 1.x,添加完Crate后先将main函数改成async:
#[tokio::main(flavor="multi_thread", worker_threads=8)]
async fn main() -> Result<(), Error> {
...
}
tokio跟Go都Go Routine类似并没有直接使用系统的线程,而是自己有一个线程池和一套Task的定义,worker_threads指定了tokio使用系统线程的数量。另外值得注意的是,跟Go类似,tokio的Task(也就是之后会用到的各种async spawn)是非常轻量的,在它们之间切换并没有很大的开销,因此完全可以向Erlang一样同时Spawn几千甚至几万个线程而不必担心它们之间会产生巨大的Overhead。这也是为什么这里能够简单的把每次递归都变成线程而不用担心性能的原因。
下一步便是把之前的for_each循环写成task的Spawn,它看起来就像是这样:
... // calculate and filter (obj, concept)
.map(|(obj, concept)| {
let r = r.clone();
tokio::task::spawn(
async move { enumerate_fc(concept, obj + 1, r, should_print).await },
)
}) {
t.await.unwrap().unwrap();
}
但这里仍然有几点需要注意:
- 由于async task的Lifetime要求要足够长(或者说是
'static),因此传递一个引用进去是无法编译的,需要把所有的内容都改成传值:
fn enumerate_fc(
cur_concept: FormalConcept,
cur_obj: usize,
r: Arc<Relation>,
should_print: bool,
)
-
这里的
Relation是读取的数据,在整个处理过程中是不变的,显然而在每次循环中都要把它传给下一个递归函数,因此不得不进行Clone,但纯粹的Clone显然很浪费,因此这里使用了Arc。 -
Rust的设计上并不支持直接对
async fn的递归调用,因此通常需要一些别的办法,而至于为什么,Rust的官方Doc里有一些解释:
fn enumerate_fc(
cur_concept: FormalConcept,
cur_obj: usize,
r: Arc<Relation>,
should_print: bool,
) -> BoxFuture<'static, Result<(), ()>> {
async move {
tokio::spawn(async move {
enumerate_fc(...).await
}
}.boxed()
}
所以,最终这个函数看起来像是这样的:
fn enumerate_fc(
cur_concept: FormalConcept,
cur_obj: usize,
r: Arc<Relation>,
should_print: bool,
) -> BoxFuture<'static, Result<(), ()>> {
async move {
if should_print {
println!("{}", cur_concept);
}
if cur_concept.extent.all() {
return Ok(());
}
(cur_obj..r.row.len())
.filter(|obj| !cur_concept.extent.get(*obj).unwrap_or(false))
.filter_map(|obj| {
let mut extent = cur_concept.extent.clone();
extent.set(obj, true);
let concept = closure(&r, &extent);
// mask: 11111111111111111 00000000000
// ----------------- -----------
// 0 ... cur_obj-1 cur_obj ...
let mask = BitVec::from_fn(r.row.len(), |i| if i < obj { true } else { false });
let mut cur_left = cur_concept.extent.clone();
cur_left.and(&mask);
let mut new_left = concept.extent.clone();
new_left.and(&mask);
if cur_left == new_left {
Some((obj, concept))
} else {
None
}
})
.map(|(obj, concept)| {
let r = r.clone();
tokio::task::spawn(
async move { enumerate_fc(concept, obj + 1, r, should_print).await },
)
}).collect::<Vec<_>>();
Ok(())
}
.boxed()
}
这里还有一个问题:如何等待所有的Task结束?
Tokio在Spawn的时候会返回一个JoinHandle,对于每个Handle都可以进行Wait,因此如果你在网上进行搜索,可以找到类似这样的做法:
for h in HandleVectors.iter() {
h.await.unwrap();
}
写进这里就像是这样的:
for i in (cur_obj..r.row.len())
....
.map(|(obj, concept)| {
let r = r.clone();
tokio::task::spawn(
async move { enumerate_fc(concept, obj + 1, r, should_print).await },
)
})
{
i.await.unwrap().unwrap()
}
编译之后让来看一看它的速度怎么样:
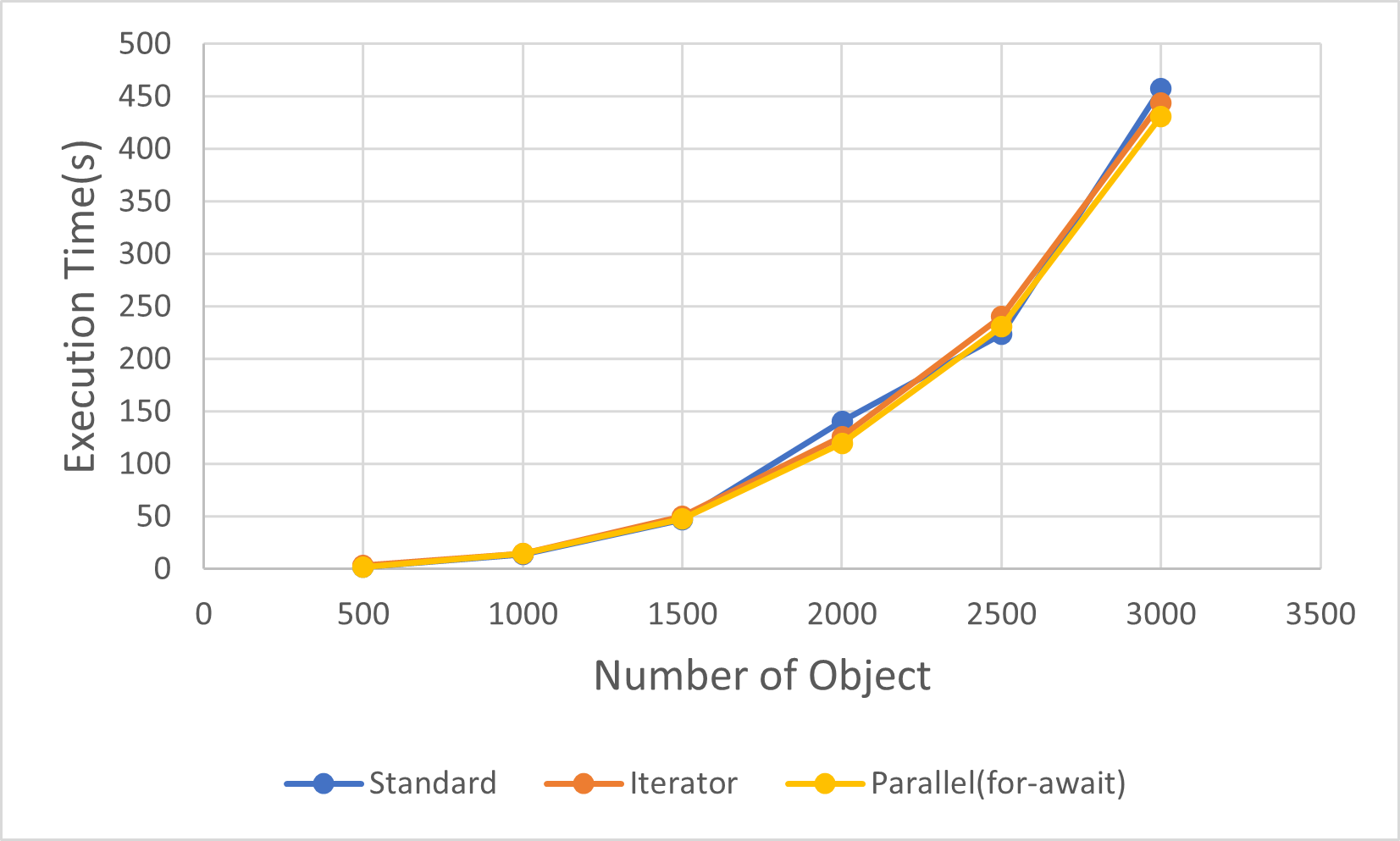
浅黄色的线是多线程版,可以看到它的速度丝毫没有变快。而至于CPU的使用率:
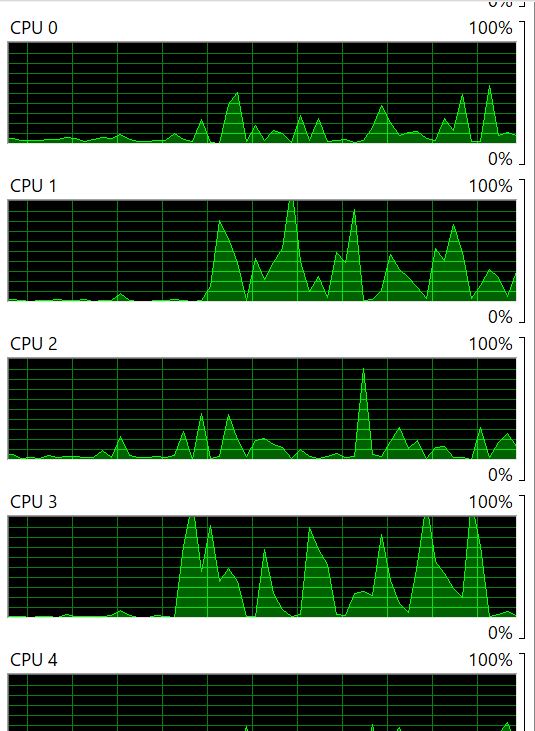
很明显这些CPU并没有被(完全)使用,原因是Iterator是Lazy的,也就是如果直接用在for里的话,里面的代码只会在next调用时才会实际计算。而由于每一次for后都会等当前任务完成,所以这个代码实际上就是个单线程。因此应该加上一个collect保证里面的内容能够先被执行:
for i in (cur_obj..r.row.len())
....
.map(|(obj, concept)| {
let r = r.clone();
tokio::task::spawn(
async move { enumerate_fc(concept, obj + 1, r, should_print).await },
)
})
.collect::<Vec<_>>() // 注意这里
{
i.await.unwrap().unwrap()
}
除此之外,future提供的join_all也可以同时处理所有的JoinHandle:
join_all((cur_obj..r.row.len())
...
.map(|(obj, concept)| {
let r = r.clone();
tokio::task::spawn(
async move { enumerate_fc(concept, obj + 1, r, should_print).await },
)
}) //join_all可以用在Iterator上,不需要collect
).await;
join_all是个Future的Wrapper,每一轮它都会检查所有的task有没有完成,如果全部完成就会返回。
总之,不论是哪一种方法都得到一个真正并列的版本了,看一下CPU,每一个都是100%的使用率:
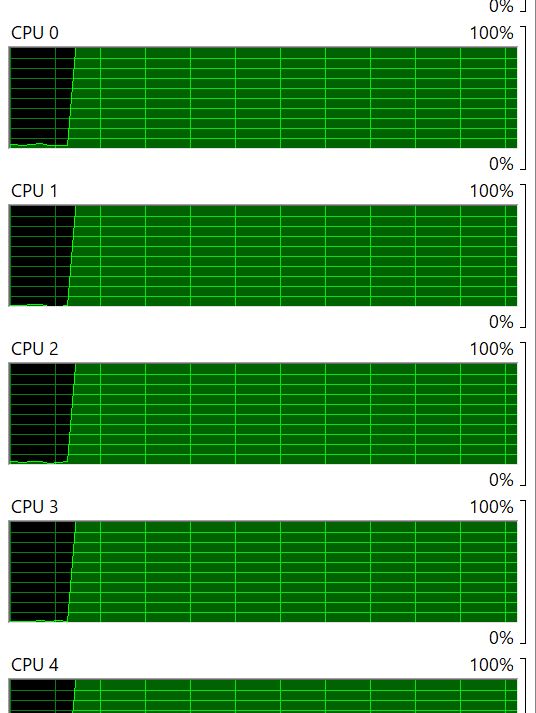
而执行速度也有了大幅的提升,对于3000 objects的数据变快了5倍:
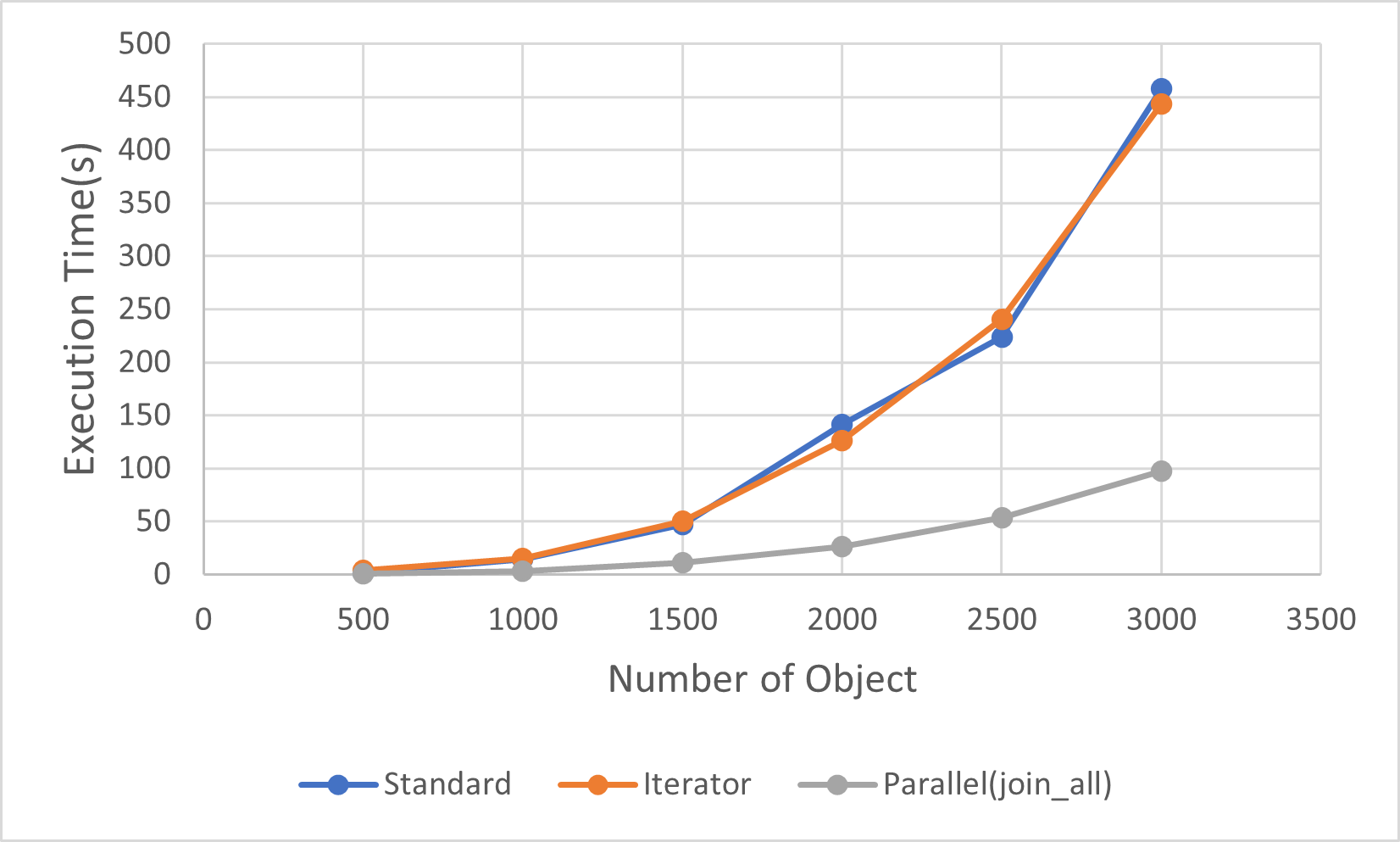
有趣的是,for - await的做法比join_all要稍微快一点点:
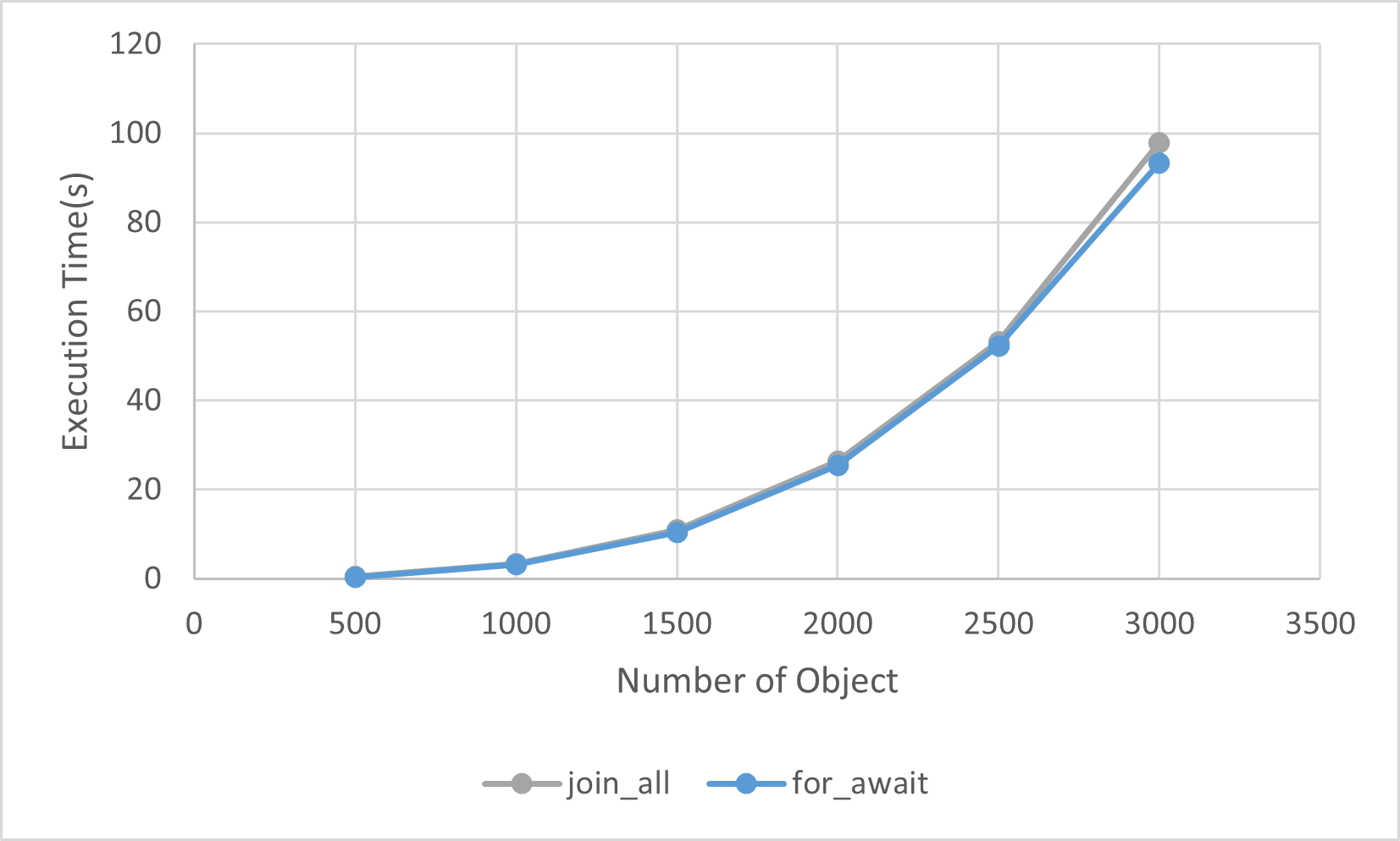
因为join_all每次都会轮询所有的task,相比于只看第一个task多少处理上会有些overhead。
到这里,第一个多线程的版本就完成了。
Impact of Number of Tasks
不过,从一开始就有的一个问题依然没有解决:这个程序对每一个分支都生成了一个Task,就算Tokio的Task非常轻量,面对几十万甚至上百万的Task,这个Overhead真的能够忽略不计吗?
总之,先来看一下执行过程中Task调度到底执行了多少次。在linux下可以用perf很轻松的得到结果,而MacOS下则要用dtrace,Windows下面通常用Windows Perform Analyzer。这里用了dtrace,得到的FlameGraph是这样的:
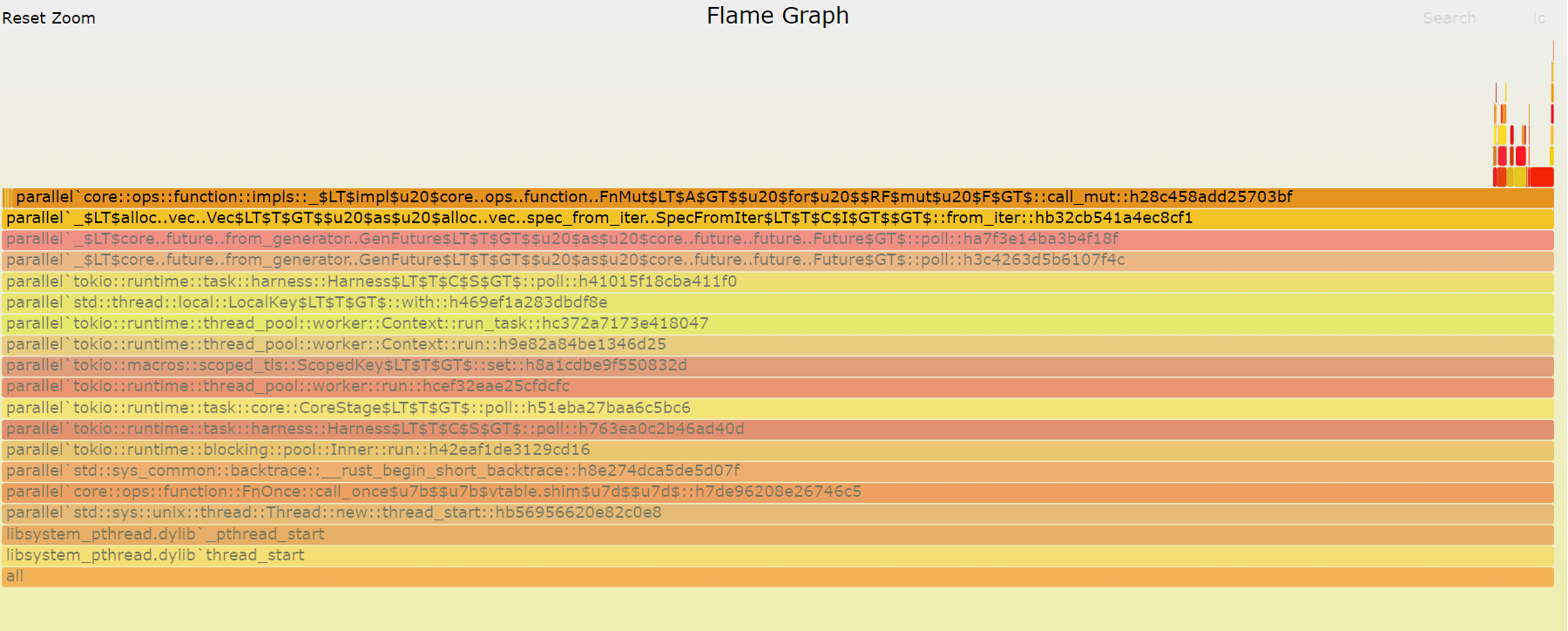
call_mut::h28c458add25703bf占据了几乎所有的执行时间,需要注意的是,这个函数其实就是enumerate_fc函数,因为为了规避递归出现的错误,这个函数返回了一个future然后在外部执行了它,因此enumerate_fc的名字不会出现在里面,取而代之的是一个async的block。而这个FlameGraph似乎没有什么问题。
不过继续尝试着减少Task的数量看看到底能不能提高性能也不是一件坏事。毕竟在这个程序中有几十万上百万个Task,改进说不定有些效果。
对于Formal Concept的Enumeration,可以通过限制并行的层数来减少Task——只有递归层数小于某一层时才能生成新的Task,否则就执行普通的单线程的列举。如果选择只对最上面一层进行Spawn,那么总的Task数跟Object的数量noo是一致的。如果对上面两层,那么Task的数量是\(\le noo \times (noo-1)\)。根据这个想法,Spawn的map改一下:
.map(|(obj, concept)| {
let r = r.clone();
if depth => max_depth {
tokio::task::spawn(async move {
enumerate_fc_seq(concept, obj + 1, &r, should_print);
})
} else {
tokio::task::spawn(async move {
enumerate_fc(concept, obj + 1, r, should_print, max_depth, depth + 1)
.await
.unwrap();
})
}
})
这里enumerate_fc_seq是一个不包含任何async代码的单线程版本,当depth大于设置的值时就停止生成新的task。
另外需要注意的是为了让类型匹配,对于单线程版本的分支也是通过tokio::spawn放到新线程里执行的——这导致了不管怎么调整参数,第一层总是并列的。为了让参数跟实际执行的结果看起来更匹配(即depth是0时应该是个单线程,而depth=1时只有第一层被并行),对于\(depth = 0\)可以在main函数里单独执行一个单线程的版本,对于\(depth = N (N>0)\)才用\(depth-1\)作为参数来执行上面这个函数。下面的测试中实际上也是这么做的。
对于这个版本,可以得出MaxDepth和执行时间的关系:

可以看到,\(depth=0\)(及纯粹的单线程)以及\(depth=1\)(只生成第一层的Task)的表现不太好,但在那之后无论如何增加depth都对结果没有太大影响。因此可以认为Tokio的Task不论如何使用,都不会对性能有着明显的伤害,反过来过分的限制Task反而会让Tokio的调度不够灵敏从而浪费CPU。
Conclusion
这篇文章实现了一个多线程版的Formal Concept Enumerator,在实现的过程中,Tokio的Task表现得比想象的要轻量的多——完全可以承受几十万甚至上百万的Task运行。不用考虑Task切换Overhead的好处是显而易见的,不再需要考虑限制线程数,只要把所有能够并行化的地方都扔给Tokio处理就足够了。
到这里,对于Formal Concept的实现就告一段落了,但实际上仍然有很多东西值得去做,比如使用MapReduce来生成Formal Concept1, 寻找更好的剪枝方法,甚至是用机器学习来生成Concept Lattice。 其实就算对于目前的内容来说,上一篇文章引用的论文2用了另外一种方法去限制Task的数量,验证它的效果也是一个值得去做的事情,不过这个工作就算是留给给读者的一个动手做吧。
-
Chunduri, Ragahvendra Kumar, Aswani Kumar Cherukuri, and Mike Tamir. "Concept generation in formal concept analysis using MapReduce framework." 2017 International Conference on Big Data Analytics and Computational Intelligence (ICBDAC). IEEE, 2017. ↩
-
Krajca, Petr, Jan Outrata, and Vilem Vychodil. "Parallel recursive algorithm for FCA." CLA. Vol. 2008. Citeseer, 2008. ↩