Things Behind ATH-DSR9bt(1)
Introduction
2014年、オーディオテクニカからフルデジタルのヘッドホンATH-DN1000USBが発売された。札幌のヨドバシで実機を聞いてから、その解像度をずっと忘れられなかった。ただし、当時としても値段がかなり高く(7万くらい)、私と同じ手を出せなかった人も多いでしょう。その結果、一時期話題になっていたが、あまり売れていなかった。
2年後、DN1000USBと同じDnote技術を使ったDSR-7/9btが発売された。Bluetooth付き、デザインも更にかっこよく、何より値段は3万~6万、もはや売れる要素しかないと思いきや、普通に売れた程度だった。ハイレゾのような怪しい概念をすんなりと受け入れられるオーディオ市場なのに、なぜフルデジタルは無視されるだろう?レビューや掲示板を見ていると、フルデジタルがよく言われるのは
- 結局アナログに変換されるでしょう?ならフルデジタルの意味はなんだ?
- 仕組み上アンプ入りのヘッドホンと何が違うんだ?
- 所詮無線だし、有線に勝てるわけがない
最後はともかく、上の2つについて私も似てる疑問があった。Dnoteの説明もオーテクのインタビューも詳細を説明されていないため、今回は色んな特許文献を見ながら、フルデジタルの原理、その特徴について述べていく。
The origin of Full-digital Audio
実はこのフルデジタルの概念は新しいものではなく、結構昔から提案されていた。特許検索してみると、こんなものが
JPS52121316A Pulse code modulated signal reproducing speaker (ソニー株式会社)
この特許はなんと1976年のもの、しかも今の文献にも引用されちゃんとしたフルデジタルの大元だ。 なので、Dnoteを語る前に、まずは当時の考え方を見ていきましょう。
PCM Audio, and Basic Structure of Headphones
ヘッドホンを語る前に、まずいくつ基本概念を理解しないといけない。最初は音声保存方式のPCM(パルス符号変調)だ:
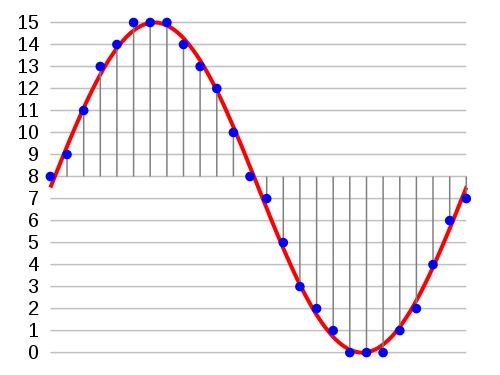
赤い線が音声信号の場合、一定の時間\(T\)毎にこの線の高さ(信号の強さ)を記録し、この高さを\(N\)段階量子化すれば、信号の近似を得られる。この記録の方法はPCMだ。 ハイレゾの「ハイ」っていうのも、元の音声を記録した時、\(N\)を増やす・\(T\)を減らすを意味している。 まとめると、音声はこんな感じでユーザの所に届いている:
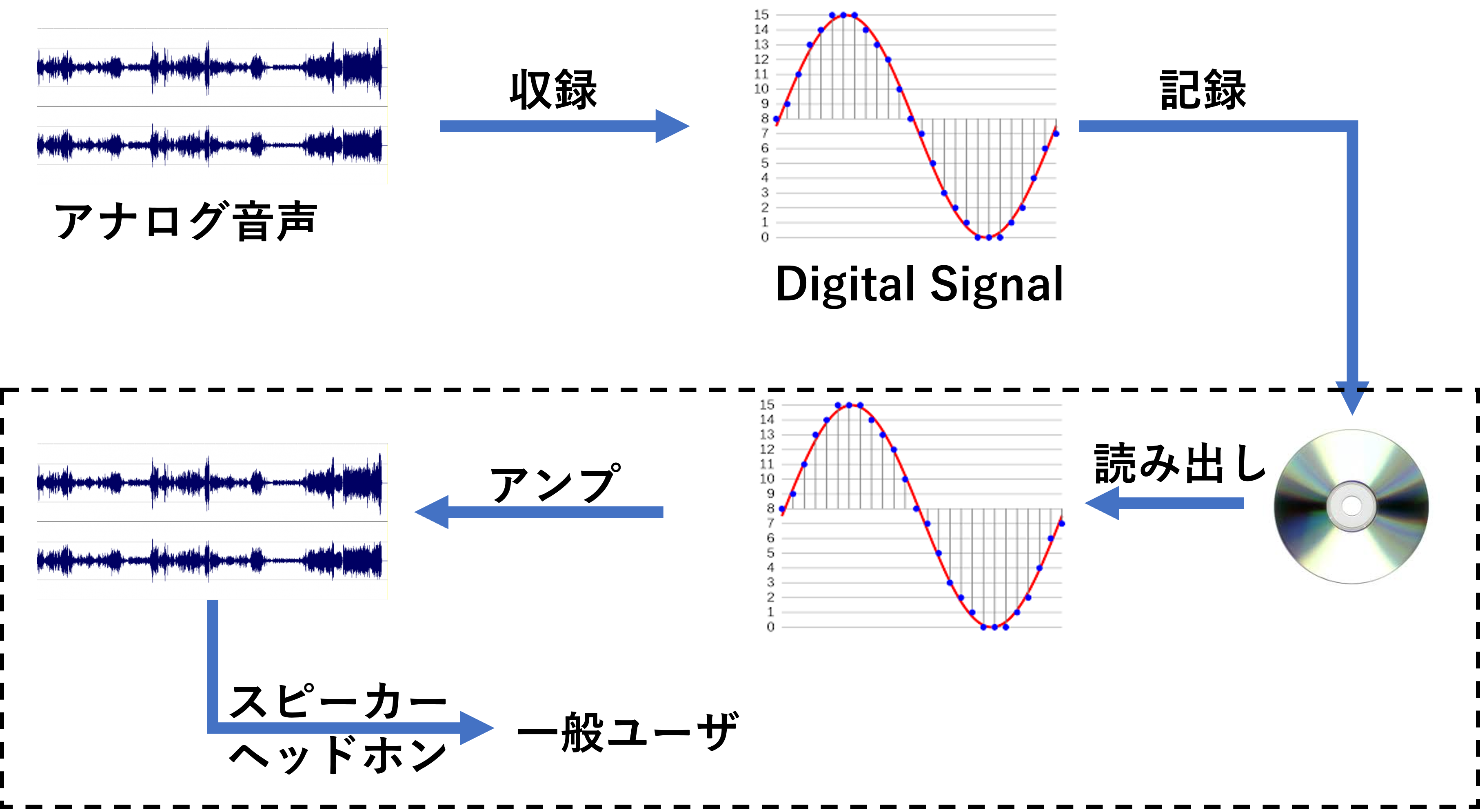
量子化された信号は最終的に(近似の)連続信号に戻され、ヘッドホンによって再現されるが、そのヘッドホンの一般的な構造はこんな感じだ:
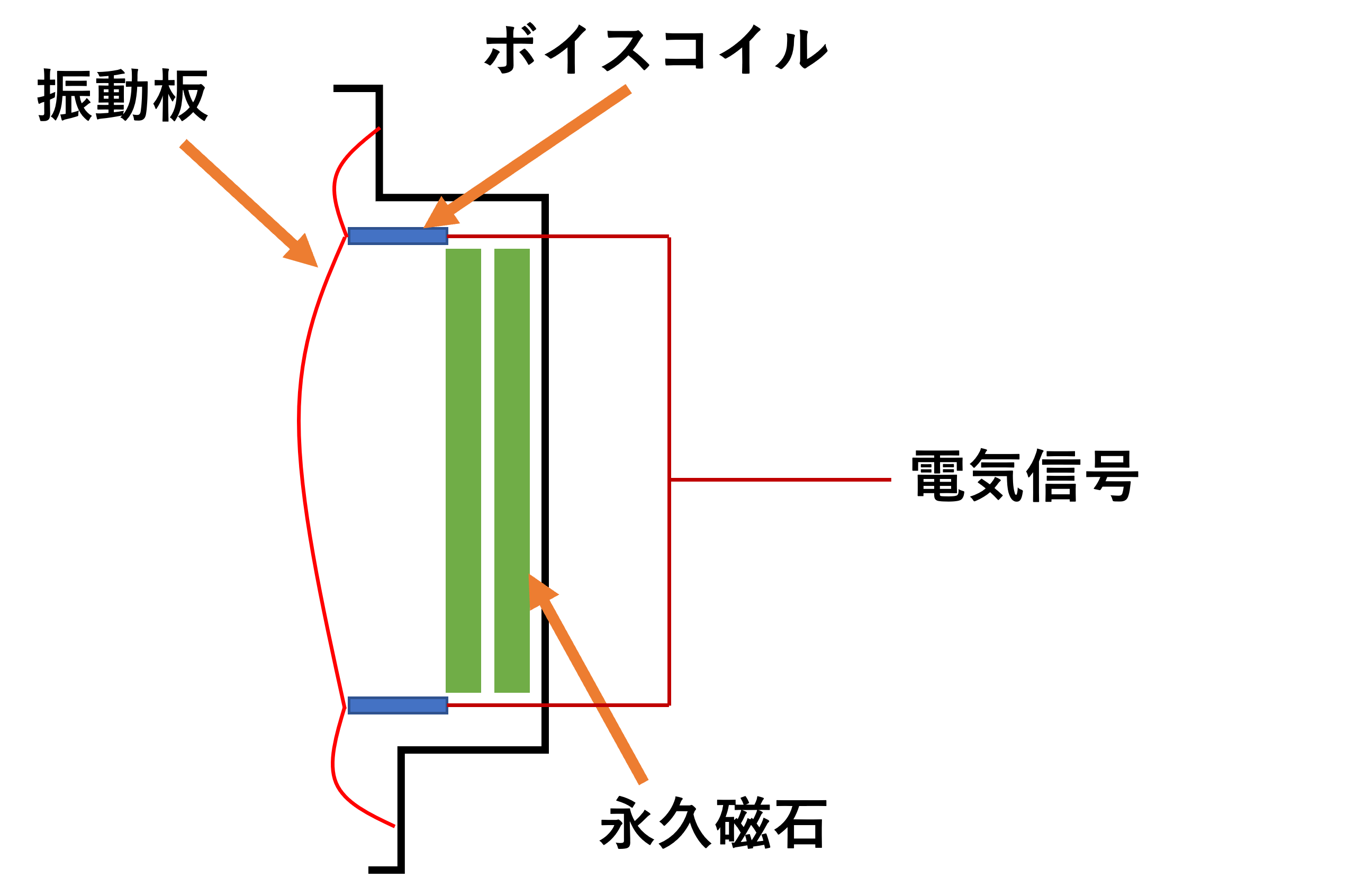
アナログの信号は電気としてボイスコイルに流れて、ボイスコイルがそれに応じて磁気を発生し前後に動く。ボイスコイルについている振動板も同時に動いて空気を動かし、電気信号による振動を空気の振動(音声)変換する。
もっと知りたい人はオーテクがいい感じの説明を用意しているのでぜひ一度見てみてください。
この図を見ればわかると思うが、
- 電気信号が如何に元の信号に近いか
- 振動板が如何に忠実に振動するか
によって音声の正確さが決まるため、今までどのオーディオ会社も高性能の振動板やよりノイズ少ない回路を作っていた。ただし、以下の問題はずっと残っていた:
一回量子化された信号は、もう元に戻せない。ならば、その戻す処理は無駄ではないか?
Full-digital Audio, First Try
その戻す処理が無駄なら、一層それをなくせばいいのでは?とソニーが考え出した。
前述の通り、信号は1つ1つの数値でしかないため、そのタイミングで振動板がその強さになっていれば、もう記録された情報をすべて表現したと言えるだろう。なので、JPS52121316Aの特許はこんなことをしていた:
強さ毎にボイスコイルを用意して、信号の強さに応じて対応のボイスコイルを鳴らす
絵で書くとこんな感じ:
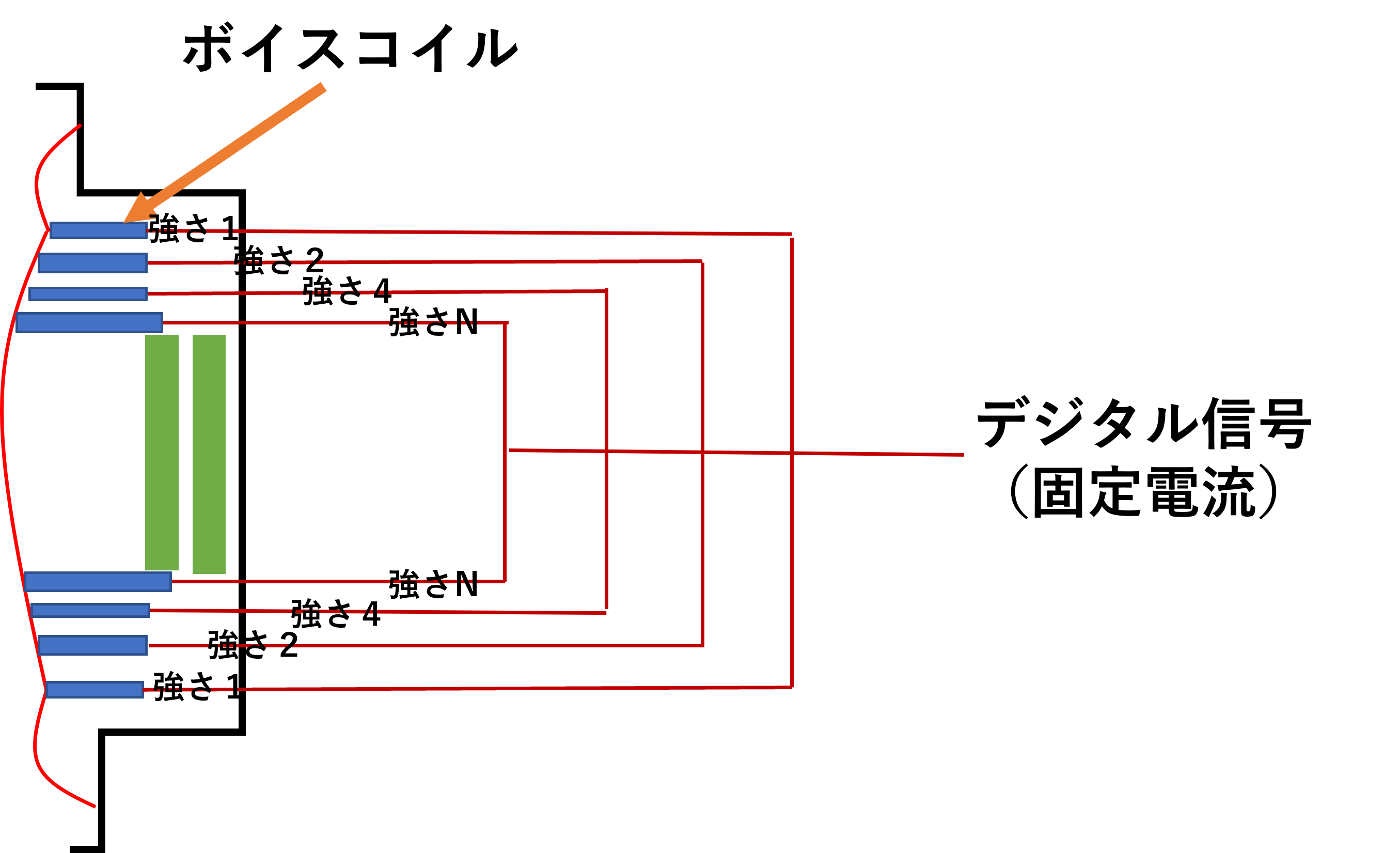
つまり、ボイスコイル1は強さ1しか出せない、ボイスコイル2は強さ2しか出せない...
そうすると、ある強さが必要の場合、そのボイスコイルを鳴らすだけでいけるのだ、電圧も電流も調整する必要はない。こう見ると、あるボイスコイルに対して状態はonとoffしかないため、デジタルそのままと言えるだろう。
また、特に注意してほしいのは今の音声の量子化ビット数は16bit以上もあるので、最低でも\(2^{16}=65536\)のパターンがある。\(65536\)個のボイスコイルを用意できるわけがないが、代わりに、ビット毎のボイスコイルを用意することが可能だ。ボイスコイルの強さを\(1,2,4,8,16,\dots\)の順に作ると、1つのボイスコイルは量子化の1ビットに相当するので、16個のボイスコイルで16ビットの音声を表現できるようになる。
ちなみに、ボイスコイルの強さは線を巻く回数によって決めているので、8bitならまだいいが、今の24bitや32bitになるとさすがに対応できなくなるだろう。
そうすると、今のフルデジタルヘッドホンはどう実現したのだろうか?次回のブログではDnote技術の特許を見ながら、実現方式を説明する。